前言
分布式是现在大多数程序必要的运行环境:单机服务如果服务器宕机了,向外提供的服务马上崩溃,整个系统陷入瘫痪;而如果存在多个服务器向外提供服务,
只要还存在提供服务的服务器,系统就能正常运行
分布式系统向外提供服务时,很多情况下都会出现多个服务器共享某一资源的情况,存在自愿竞争;
如:
商品系统提供了rpc 接口,功能是创建商品信息,这个rpc 接口的提供服务器有 A,B,C;
这个创建商品信息的接口,在创建新的商品之前,会检测现在是否已经存在该商品,如果存在则返回已存在该商品,否则将新建商品
rpc接口的消费者是E, 假设 E 第一次调用的时候调用的是A,在短时间内再次请求,创建相同的商品,这时候A 服务器还没处理完,假设请求分发到了B
这时候 A 服务器还没有将商品信息持久化, B 服务器已经运行到了检查是否已经存在该商品, B 服务器没有查询到商品已存在,又创建了一个商品,此时商品的唯一性时效!
1 | public Result createProduct() { |
面对上述问题,在单机服务器上,我们很容易想到给 createProduct 加锁,使该方法实现线程安全; 将这个思路扩展到分布式系统,我们能否提供一个适用于分布式系统的锁?
要实现分布式锁,我们需要借助工具
“1. 数据库
- redis
- zookeeper
1. 依赖数据库实现分布式锁
各种版本的数据库都实现了锁,这里以 mysql 的 InnoDB 存储引擎为例;
InnoDB 的特性是:支持事务、支持行级锁、支持外键;
InnoDB 提供了两种类型的行级锁:
“1.共享锁(S): 允许一个事务去读一行数据,阻止其他事务获取相同数据集的排他写锁
2.排他锁(X): 允许获得排他锁的事务修改一行数据,阻止其他事务获取相同数据集的共享读锁和排他写锁
对于 DELETE、UPDATE、INSERT语句,InnoDB会自动给涉及到的数据集加上排他锁;
对于普通的 SELECT 语句,InnoDB 不会加上任务锁;
而 事务 可以通过以下语句显式的给涉及到的数据集加上共享锁或者排他锁:
“1. 显式添加共享锁
1 | SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE; |
- 显式添加排他锁
1 | SELECT * FROM table_name WHERE ... FOR UPDATE; |
FOR UPDATE 添加排他锁,后一个想要获取锁的事务,会等待前一个事务的完成之后才能获取排他锁
回到正题,我们上面所说的分布式锁,需要具备排他性;事务 通过 FOR UPDATE 添加排他锁正好满足我们的需求
1 | def lock: |
这里使用的 事务 + FOR UPDATE 添加排他锁
1 | package com.liam.distribute.lock.db; |
上面这种实现分布式锁的方法存在一些问题:
“1. 性能不是很高
- 这里加锁解锁依赖sql,必须面对sql超时问题,如果底层 jdbc 和 数据库之前的socket 超时了,此时connection 基本不可用,需要关闭;
因此,在使用Connection的时候,推荐的使用方式是,将Connection的生命周期控制在一个方法内; - 如果调用分布式锁的消费者宕机了,没有人去解锁,其他消费者将无法获取锁
- 没有可重入性
除了上面说的 依赖 事务 通过 FOR UPDATE 实现分布式锁; 我们还能通过 唯一索引 实现分布式锁
先看看建表语句:
1 | create table uniq_lock_table ( |
简单定义一个dao 层接口
1 | package com.liam.distribute.lock.mapper; |
分布式锁简单定义如下:
1 | def lock: |
用java 实现的代码如下:
1 | package com.liam.distribute.lock.db; |
上面这种方法的缺点很明显:
“1. 分布式锁不具备可重入性
- 如果某一消费者在获取锁之后宕机了,其他消费者无法获取锁
为了解决 上面反复提到的 失效的锁的问题,我们在获取锁的时候新增时效时间!
1 | def lock: |
java 实现如下:
1 | package com.liam.distribute.lock.db; |
上面这些方法都没能实现分布式锁的可重入性,这里需要新增一个字段,标明分布式锁是谁加的, 再来看看新增分布式锁调用方标识之后的分布式锁定义
1 | def lock: |
在使用上面这种方式实现可重入性的时候,需要将表中的唯一索引修改一下
1 | alter table add UNIQUE INDEX `uniq_lock_key_biz_uniq_code`(`lock_key`, `biz_uniq_code`); |
注意: 上面说的这些依赖数据库实现分布式锁,都要避免单数据库示例的问题,如果只有一个数据库示例,而数据库宕机了,分布式锁将不能提供服务;因此,分布式锁依赖的数据库必须配置多数据库实例,利用数据库的主从复制逻辑,保证数据同步!
2. 依赖redis实现分布式锁
redis 作为内存数据存储系统,相比数据库具有更好的高可用性
先来看看一个 redis 命令, setnx
\> help setnx
SETNX key value
TIME COMPLEXITY: O(1)
RETURN VALUE: Integer reply, specifically:
1 if the key was set
0 if the key was not set
从帮助信息能看明白, setnx 功能和 set指令类似, 不同在于 setnx 只有插入的key 不存在的时候才能插入成功,成功之后返回 1, 失败返回 0
我们依赖 setnx 实现分布式锁,定义如下:
1 | def lock: |
上面的定义存在的问题有:
“1. 调用分布式锁的消费者如果在获取锁之后宕机了,这个失效锁将导致其他消费者无法获取锁
- 分布式锁不具备可重入性
为了提供更好用的分布式锁,我们必须给分布式锁加上时效性
下面来看看 redis 的 set 指令
> help set
SET key value
TIME COMPLEXITY: O(1)
Options
EX seconds -- Set the specified expire time, in seconds.
PX milliseconds -- Set the specified expire time, in milliseconds.
NX -- Only set the key if it does not already exist.
XX -- Only set the key if it already exist.
RETURN VALUE: Status code reply: OK if SET was executed correctly. Null multi-bulk reply: a Null Bulk Reply is returned if the SET operation was not performed becase the user specified the NX or XX option but the condition was not met.
从这个可以看出来,set 指令可以做到 setnx 指令的目的,如下:
1 | set key value NX |
再看看下面的指令
1 | set key value EX 10 NX; //插入一个 k-v 数据,只有key不存在的时候才能插入成功,插入成功好,10s 内数据有效,10s 后数据失效将被删除 |
加入有效时间后,分布式锁不需要在每次加锁之前清除无效锁, 得到优化的分布式锁如下:
1 | def lock: |
上面的分布式锁还是没有实现可重入性, 改进如下:
1 | def lock: |
依赖 redis 实现 分布式锁 存在一个难以解决的问题,redis 不能保证数据的 强一致性, 因为;
redis 集群使用异步复制
如果在加锁的时候 redis 的 master 宕机了,异步复制到 slave 失败了,加锁就失败了!
为了解决这个问题,redis 的作者提出了 redLock
RedLock
这里不对 RedLock 进行介绍,详情见 并发编程网 翻译
http://ifeve.com/redis-lock/
3. 依赖zookeeper 实现分布式锁
ZooKeeper 能被用来实现分布式锁的原因取决于他的以下几个特性:
“1. ZooKeeper 的视图结构和 unix 系统的文件系统类似,都是采用树结构,不同的是 ZooKeeper 的树结构上是新定义的 数据节点 —— ZNode,ZNode 是 ZooKeeper 中数据的最小单元,可以保存数据,也可以挂靠子节点;
ZooKeeper中的ZNode的类型分为持久节点、临时节点、顺序节点三大类型;通过组合使用可以生成四种节点:
“1)持久节点:是指该数据节点被创建之后,就一直存在于ZooKeeper服务器上,直到有删除操作来主动清除这个节点;
2)持久有序节点:和持久节点的基本特性一致,不同的特性在于顺序性上;在ZooKeeper中父节点会为它的第一级节点维护一份顺序,用于记录下每个子节点创建的先后顺序。
3)临时节点:和持久节点不同的是,临时节点的生命周期和客户端的会话相关,如果客户端会话失效了,临时节点将被自动清除。
4)临时有序节点:和临时节点的基本特性一致,不同的特性也在于顺序性上;ZooKeeper机制规定:同一个目录下只能有一个唯一的文件名。例如:我们在Zookeeper目录一个目录下创建,两个客户端创建一个名为new_node节点,只有一个能够成功。ZooKeeper提供Watcher机制,客户端可以在服务端注册一个Watcher监听,当服务端的一些指定事件触动了这个Watcher,就会向客户端发送通知
获取锁
依赖上述特性,我们可以在 ZooKeeper 的树结构上,创建一个临时节点 /distribute_lock/lock, 只要有一个客户端创建了节点,表示该客户端获取到了锁;
而其他没有获取到锁的客户端,需要到 ZooKeeper 的 /distribute_lock 节点上注册一个子节点变更的 Watcher 监听,以便见听到子节点的变更情况。
— distribute_lock
— lock
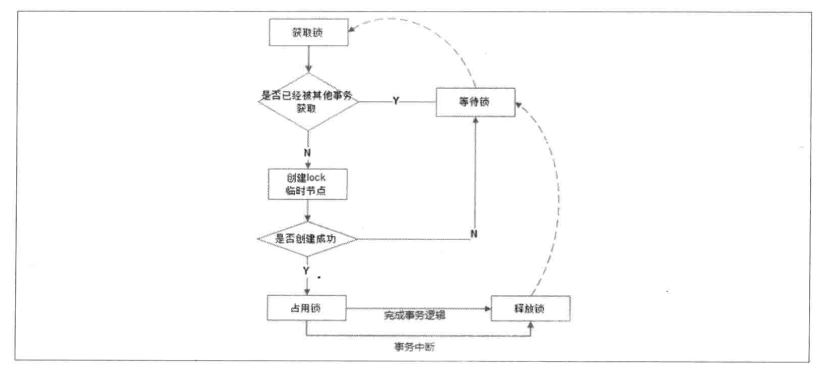
释放锁
“1) 客户端执行完业务逻辑后,主动删除自己创建的临时节点;
2) 客户端宕机后,ZooKeeper 和客户端之间的对话失效、连接断开,客户端创建的临时节点将被自动删除
3) 客户端释放锁之后,其他客户端通过 Watcher 监控得到锁被释放的通知,而来竞争获取锁